音楽生成モデルの動向と楽曲体験デザインへの応用可能性について (2021)
この記事は Medium に掲載した記事の抜粋・修正した転載です。
シンボリック音楽生成モデルの動向
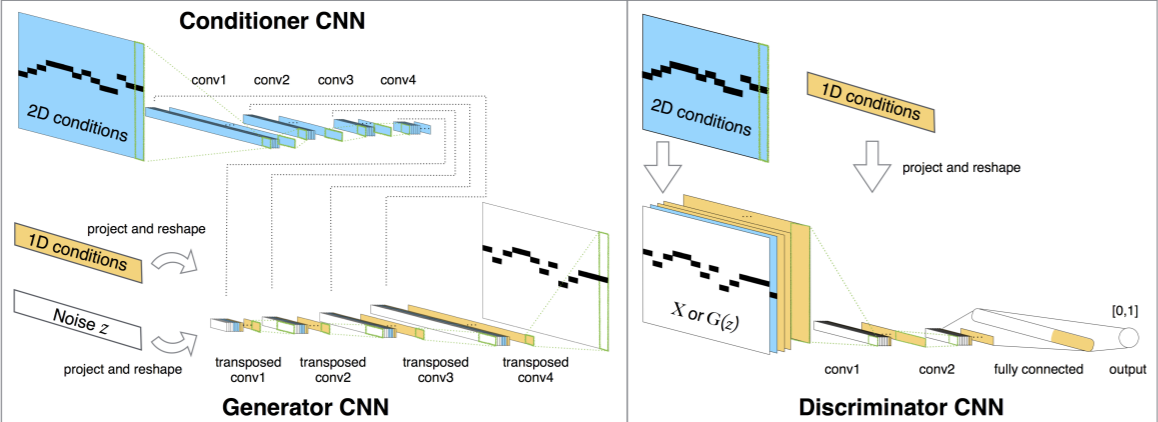
深層学習モデルを用いたシンボリック音楽生成は近年様々な手法が検討されており GAN (MidiNet 等) や RNN, VAE を組み合わせたもの (PerformanceRNN, MusicVAE 等) が提案されている。その中でも,2018年に Google Magenta が発表した Music Transformer ではそれまでのモデルと比較しより長期的な依存関係を表現することができるようになり,その後は Transformer をベースとした様々な音楽関連のタスクを解くモデルが提案されている。
まず機械学習を用いてシンボリックな音楽情報を扱うには,大きく分けて2つの手法がある。一つは深層学習モデルで扱うためのマトリクス表現に変換する方法で,MIDI のピアノロールを画像として扱うのに近い。扱える音階,音量を16分音符等に設定された各グリッド上に配置したものを予測する。
MidiNet 論文より引用 h=128, w=16 などの行列表現になっている
一方は MIDI の各イベントを単一のシーケンスとして扱うために note on や note off,time shift (milliseconds) 等のイベントすべてを one-hot encoding し,各イベントを系列として扱う手法である。マトリックス表現にする時と比べデータが疎になりにくく(例えば4拍の休符があった場合16分音符のステップでは16このデータがゼロとなるが Rest トークンがあればより少ないデータ数で表現できる),言語モデルのように系列としてデータを扱うことで学習を可能にしている。
この MIDI データをトークナイズする手法も様々提案されている。例えば Music Transformer や PerformanceRNN で用いられている表現の MIDI like representation では,Pitch 情報を持った Note-On と Note-Off,Time-Shift (ms) と Velocity(音量)がそれぞれトークンとして順番に羅列している。
上記の楽譜を MIDI Like Representation でエンコードしたトークン表現(MidiTok リポジトリより引用)
その後 Pop Music Transformer (ACM MM 2020) で提案された REMI では,各トークンを小節ごとにまとめるために Bar トークンを採用し,Time-delta を廃止し各小節の頭から何グリッド目かという Position トークンと,音符の持続時間を表現する Duration トークンで時間情報を扱っている。
また,PopMAG: Pop Music Accompaniment Generation (demo, ACM MM 2020) で用いられている MuMIDI という手法では,マルチトラックに対応するために楽器の種類を表す Track トークンや Chord トークンが採用されており,ドラムのピッチとその他の楽器のピッチ情報は別々のものとして扱われている。
またモデルの内部では時系列を扱う Bar や Position と,音符を扱う Pitch,Velocity と Duration は別々の空間へと埋め込まれている。これらのエンコーディング手法をまとめたオープンソースのトークナイザライブラリ MidiTok が実装され,昨年の ISMIR2021 で発表されている (MIDITOK: A PYTHON PACKAGE FOR MIDI FILE TOKENIZATION, GitHub)。
さらに,SFUの Metacreation Labの MMM (Mutitrack Music Machine) では,MIDI で扱える全ての楽器を指定した生成が可能である。
内部的には GPT-2 が用いられており,生成時にはトラック開始と楽器を指定するトークンまでをプライミングとして入力することで,その続きを予測する形で任意の楽器でのメロディ/伴奏/リズム生成を行うことができる。さらに Density トークンによって,音価の密度 = どれくらいの音数にするかまでコントロールができるようになっている。
また,先日の ACM MM 2021 の best paper であった Video Background Music Generation with Controllable Music Transformer では映像データから BGM を生成しているが,その際にジャンルを指定して生成することが可能になっている。
このように,Transformer ベースの生成を行うシンボリック音楽生成のモデルは単なる表現力のみならずコントロール可能な域まで達しており,様々な応用方法が考えられる。
応用方法として
まず第一にそれらの音楽生成モデルの応用先として考えられるのは作曲支援であろう。
実際に AI による作曲を謳ったソフトウェアやツールは様々なところがリリースしており,Google Magenta も Magenta Studio という Ableton Live 向けツールを配布提供している。ヒトの創造性を拡張するという観点から,作曲支援ツールのインターフェースに関する研究も様々なアプローチでなされており,いかに分かりやすいコントロールをさせるか,いかにユーザーであるミュージシャンに使ってもらうかという挑戦がなされている。
一方で,より豊かな音楽聴取のためのデータ活用というと,一般的には楽曲のレコメンデーション手法などに着眼点が置かれたものが多い印象があり,近年の高い表現力を持ったモデルを用いた自律的かつ実時間的な作曲によって新たな音楽体験を提供しようという試みは少ないのではないか。
例えば,上記の自律的な音楽生成モデルは今までにあった楽曲の前半部分を入力することで,既存のものとは異なる後半部分を生成することができる。ユーザーが知っている曲に似てるけど知らない曲を提供するというのは,ミュージシャンにしかなせない芸であるが,楽曲の特徴をうまく掴んだモデルなら可能であり,新しい音楽作品の形として,前半部分は固定だが後半部分は "人工知能によるインプロビゼーション" であり聴くたびに様子が異なる楽曲があっても面白い。また,既存の楽曲に対して似た曲をマッシュアップするのではなく,その場で似た曲を生成してマッシュアップし AI-Remix を作成するなどの楽しみ方もある。
おわりに
音楽生成モデルの発展にともない,作曲段階にも音楽聴取段階にもどちらにも応用し,新たな音楽体験,新たなエンターテインメントの形をつくりだすことができるのではないかと考えている。いつか人工知能とセッションをしたり,人工知能から音楽制作のアプローチを教わったりするようなインタラクションも設計されうるし,聴くたびに少しずつアレンジが替わるようなライブ感をもった今までにない音楽の聴き方もデザインされうるであろう。私個人としては引き続き生成手法のサーベイと実験,作品の製作を通して,そのような世界に近づけていくための貢献ができれば幸いである。