リアルタイムなYOLOv8推論をブラウザで動かす
パフォーマンス作品 Adaptive Generative Output Performance 2024 の開発に関わる中で,最初のプロトタイプとして YOLOv8 のリアルタイム物体検出をブラウザ上で動かす Webアプリを開発しました。

ブラウザで動作させるモチベーション
パフォーマーが使うアプリをリモートで継続的に提供するには,インストール不要で,URLを開くだけで使えるWebアプリ が最適だった。
- ネイティブアプリだとビルドの配布やバージョン管理が煩雑になる
- Webアプリであればサーバ側を更新するだけでパフォーマー全員に即時反映できる
- カメラへのアクセスはブラウザのMediaDevices APIで対応可能
物体検出モデルの推論はサーバへのリクエストなしにクライアントサイドで完結させたかった。レイテンシの問題と,パフォーマンス環境でのネットワーク不安定リスクを避けるため。そこで注目したのが WebAssembly (WASM) を使ったブラウザ内推論。
技術スタック
| 要素 | 採用技術 |
|---|---|
| フレームワーク | React + TypeScript |
| モデル | YOLOv8n (Ultralytics) |
| モデル形式 | ONNX |
| 推論エンジン | onnxruntime-web |
| バックエンド | WebAssembly (wasm) |
YOLOv8モデルをONNX形式にエクスポートする
Ultralytics の Python パッケージを使えばワンライナーでエクスポートできる。
from ultralytics import YOLO model = YOLO("yolov8n.pt") model.export(format="onnx", imgsz=640, opset=12) # => yolov8n.onnx が生成される
opset=12 を指定しているのは,onnxruntime-web がサポートするオペレーターセットに合わせるため。生成された yolov8n.onnx をそのままプロジェクトの public/ ディレクトリに配置する。
onnxruntime-webでONNXモデルをロードして推論する
onnxruntime-web は Microsoft が提供する ONNX Runtime の JavaScript/WebAssembly 実装。バックエンドとして wasm を指定するとブラウザ内の WebAssembly で推論が走る。
npm install onnxruntime-web
import * as ort from "onnxruntime-web"; // WASMバックエンドを明示的に指定 ort.env.wasm.wasmPaths = "/ort-wasm/"; const session = await ort.InferenceSession.create("/yolov8n.onnx", { executionProviders: ["wasm"], });
wasmPaths には node_modules/onnxruntime-web/dist/ 以下の .wasm ファイルを静的ファイルとして配信するパスを設定する。
カメラ映像をモデルに入力する
getUserMedia でカメラ映像を取得し,<video> 要素から <canvas> 経由でフレームを切り出す。
const stream = await navigator.mediaDevices.getUserMedia({ video: true }); videoRef.current!.srcObject = stream;
フレームの前処理(リサイズ・正規化・NCHW変換)を行い,Float32Array のテンソルを作る。
const preprocess = ( canvas: HTMLCanvasElement, modelWidth: number, modelHeight: number, ): [ort.Tensor, number, number] => { const ctx = canvas.getContext("2d")!; const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height); const { data, width, height } = imageData; const input = new Float32Array(modelWidth * modelHeight * 3); const xRatio = width / modelWidth; const yRatio = height / modelHeight; for (let y = 0; y < modelHeight; y++) { for (let x = 0; x < modelWidth; x++) { const srcX = Math.floor(x * xRatio); const srcY = Math.floor(y * yRatio); const srcIdx = (srcY * width + srcX) * 4; // NCHW形式に変換 (R, G, B チャンネルを分離) input[y * modelWidth + x] = data[srcIdx] / 255.0; // R input[modelWidth * modelHeight + y * modelWidth + x] = data[srcIdx + 1] / 255.0; // G input[2 * modelWidth * modelHeight + y * modelWidth + x] = data[srcIdx + 2] / 255.0; // B } } const tensor = new ort.Tensor("float32", input, [ 1, 3, modelHeight, modelWidth, ]); return [tensor, xRatio, yRatio]; };
推論と後処理
推論結果は [1, 84, 8400] の形状のテンソルとして出力される(YOLOv8 の場合,84 = 4座標 + 80クラス)。Non-Maximum Suppression (NMS) を適用して最終的な検出結果を得る。
const runInference = async ( session: ort.InferenceSession, tensor: ort.Tensor, ) => { const feeds = { images: tensor }; const results = await session.run(feeds); const output = results[session.outputNames[0]].data as Float32Array; // output shape: [1, 84, 8400] const [boxes, scores, classIds] = postprocess(output, xRatio, yRatio); return { boxes, scores, classIds }; };
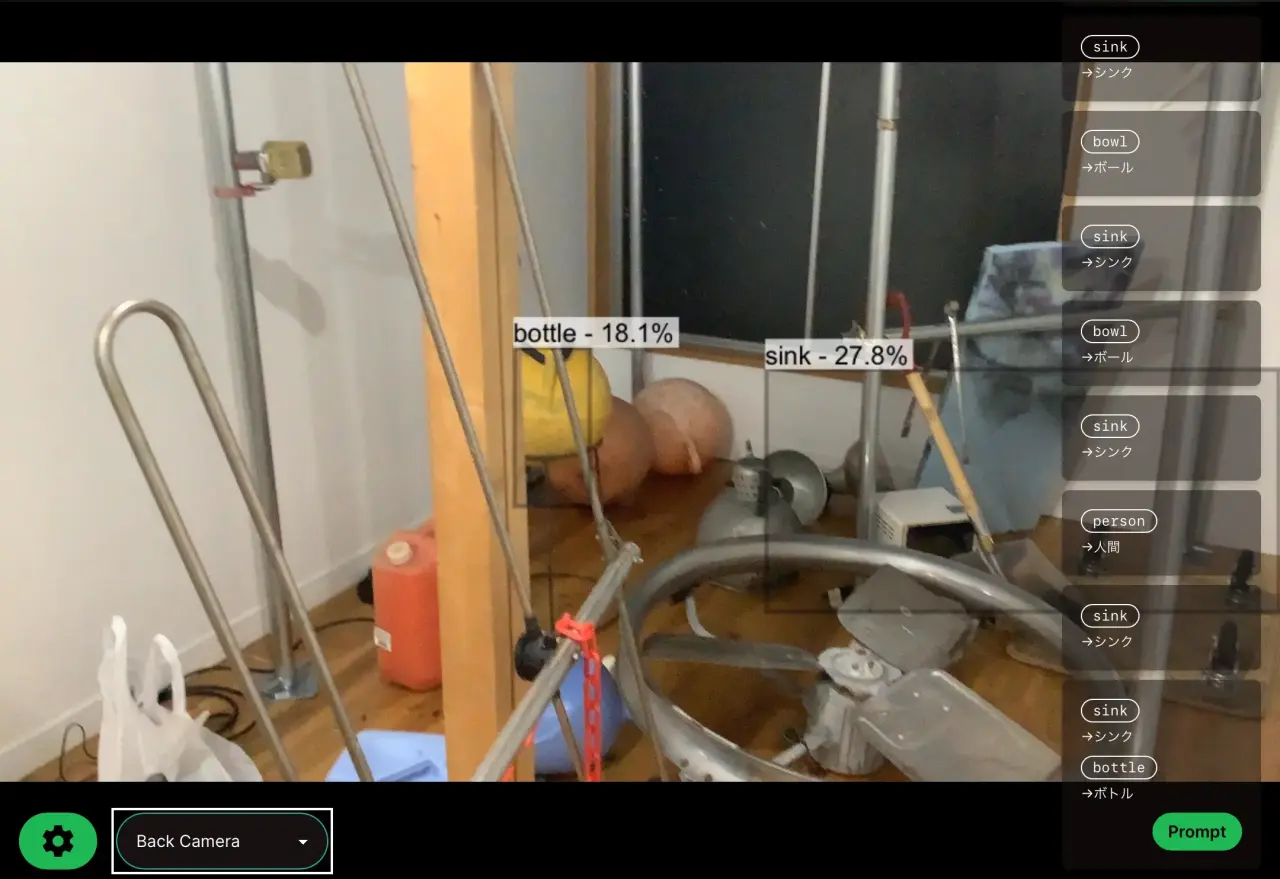
後処理では信頼度スコアでフィルタリングし,NMS を適用する。最終的な結果を <canvas> にバウンディングボックスとして描画する。
推論速度
M1 MacBook Pro の Chrome 上では 約 30ms/フレーム 程度で推論できた(YOLOv8n, 640×640 入力)。パフォーマーのマシンスペックにもよるが,リアルタイム性として十分実用的な速度。
WebGL バックエンド(executionProviders: ["webgl"])に切り替えるとさらに高速化できる場合があるが,モデルのオペレーター互換性の問題から今回は WASM を採用した。
まとめ
- YOLOv8 を ONNX 形式でエクスポートし,onnxruntime-web の WASM バックエンドでブラウザ上推論を実現した
- URLを開くだけで動く Webアプリにすることで,パフォーマーへの継続的なアプリ提供が容易になった
- サーバ通信なしのクライアントサイド推論によって低レイテンシかつオフライン環境でも動作する